Scalable Inference for Growth Recommendations
![]() Sumeet Kumar & Max ZhaoJul 31, 202515 min
Sumeet Kumar & Max ZhaoJul 31, 202515 min
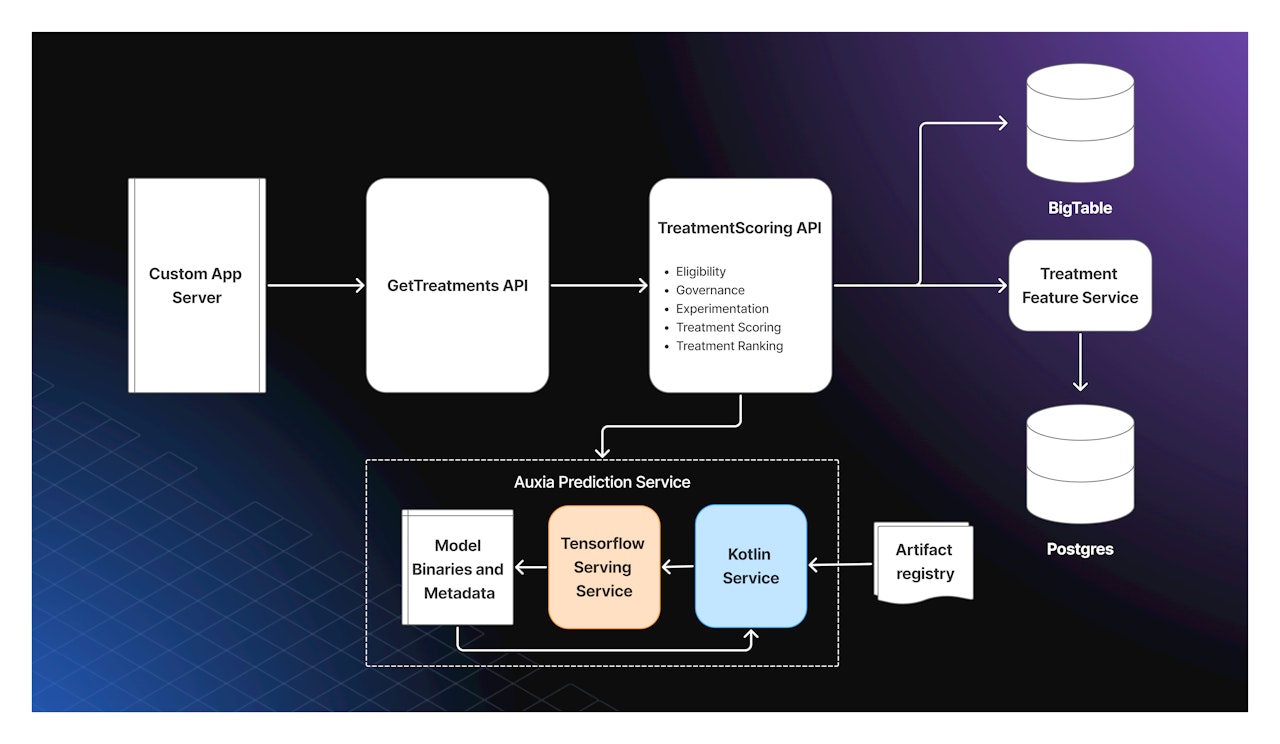
Auxia is an Agentic Customer Journey Orchestration platform that delivers personalized marketing recommendations to enterprise customers. Customers integrate with Auxia by calling our API to retrieve a recommended treatment—what we call a “Decision”—across in-app surfaces, emails, or other digital experiences.
When you’re serving enterprise customers, any infrastructure faces significant scaling challenges. We presently handle a peak rate of over 6,000 requests per second (RPS), aiming for a 99th percentile prediction latency of 100ms. Each request requires selecting from approximately 1,000 potential user-facing treatments.
This post details how we built a high-performance inference infrastructure that meets those demands.
Scaling Real-Time Personalization
Three critical requirements drive our architecture decisions:
High-volume, low-latency processing - Supporting thousands of concurrent requests with sub-100ms response times
Real-time contextual data integration - Incorporating fresh user context and behavioral data to deliver relevant recommendations
Multi-tenant model support - Running simultaneous inference across different models for each customer and goal combination
This combination of requirements demanded a high-performance, real-time inference system with dynamic model loading capabilities across load-balanced service instances.
Architecture: Kotlin + TensorFlow Serving Sidecar
We implemented a co-located system where a Kotlin server (our control plane) sits alongside a TensorFlow Serving binary (inference engine) within each Kubernetes pod. This design gives us both high performance and maximum flexibility through clear separation of concerns:
Kotlin server: Handles dynamic model loading, model metadata, input/output tensor transformation, and lifecycle orchestration.
TensorFlow Serving: Efficiently loads and executes predictions on trained TensorFlow models using a high-throughput gRPC API.
This separation of concerns ensures that model logic stays isolated, while all orchestration and business logic live in Kotlin.
As a Kotlin + gRPC organization, this design leverages Kotlin's strengths—particularly coroutines for async programming—while abstracting away ML infrastructure complexity. The Kotlin layer handles:
Infrastructure abstraction - Hiding complexities of different model types and future ML frameworks (ONNX, TorchServe, hosted services)
Dynamic model management - Loading models from our artifact registry and managing TensorFlow Serving's ModelService
Contract translation - Converting user and treatment features into model input tensors, and output tensors back into treatment scores
Why TensorFlow Serving?
We chose TensorFlow Serving over alternatives like TorchServe for several key benefits:
gRPC API advantages: strongly-typed, programmatically defined interface with binary serialization that reduces message size and CPU parsing overhead, which is critical given our large feature sets.
High performance: C++ implementation designed natively for multi-threaded usage to deliver the speed required for real-time decisioning.
Production-ready features: built-in support for dynamic model loading and automatic inference batching.
However, Tensorflow Serving introduced several challenges that needed to be addressed by the Kotlin Server:
Dynamic loading limitations - While technically supported, the binary is optimized for static model sets at startup
Limited production testing - Fewer real-world deployments mean issues like incorrect CPU detection in containers
Optimization requirements - Not all TensorFlow operations are performant, requiring careful model contract design
Inference Abstraction Layer
Our Prediction Service abstracts inference complexity into a simple, treatment-oriented API. This enables support for diverse model architectures ranging from Bandits to Tree-based Uplift models to even Deep Learning based recommender models.
Key Features
Unified API: Single, consistent interface independent of underlying model implementation. The API contract specifies flexible input formats for user features (accepting either generic key-value pairs or a structured attribute object) and a standard key-value format for treatment features. It also defines the exact output structures that models must return, such as a single score or a list of scores per treatment.
Dynamic Model Management: Load and serve different models on-the-fly without restarts, allowing for seamless updates and experimentation.
Built-in Monitoring: Automatic collection of key performance metrics (like latency and error rates) for every prediction, ensuring system health and reliability.
Developer-Friendly Tools: Model inspection capabilities and safe testing APIs for non-production validation.
Input Contract Design For Optimized Inference
TensorFlow Serving requires model inputs as a flat namespace of named tensors, essentially a flat dictionary mapping tensor names to data. Unlike TensorFlow Python’s support for complex nested structures (tuples, dictionaries, RaggedTensors), TensorFlow Serving imposes stricter requirements for serving models in production. This creates challenges when representing structured user and treatment features at scale.
Performance Optimization Journey
We experimented with several input designs to find the most efficient approach:
Initial approach: One tensor per feature with feature names as keys. Simple to implement but highly inefficient; tens of thousands of tensors per request created significant serialization and name resolution overhead.
tf.Example approach: Encoding features into TensorFlow's standard serialized format. Failed to improve latency due to costly proto parsing during inference.
Final optimized design: Collapsed same-type features into single-typed tensors, distinguished by index positions. This approach minimized tensor count while aligning with TensorFlow's internal feature resolution.
Implementation Details
User features are packed into typed tensors like [None, 4] for numerical features, where indices correspond to specific attributes (signup age, LTV, etc.).
Treatment features use [None, None, N] format supporting multiple treatments per user, with an accompanying treatment_counts tensor indicating treatment boundaries per user.
GPU optimization leverages TensorFlow Serving's auto-batching. The treatment_counts tensor handles padding removal and correct treatment boundary reconstruction.
Metadata coordination ensures alignment between training and serving through embedded metadata files that map tensor indices to human-readable feature names.
This optimized design enables us to serve large-scale real-time inference at p99 latency under 100ms while scoring up to 1,000 treatments per request at 6,000 QPS.
Serving Model Validation Framework
Every trained model must be compatible with our Prediction Service API. We built a comprehensive local testing framework with three stages:
Environment Setup
Complete, self-contained production stack instance including Kotlin Prediction Service and TensorFlow Serving process. Programmatically launched locally by fixtures to test against actual service binaries, not mocks.
Test Orchestration
Managed by pytest and helper classes that handle model artifact placement and provide high-level client abstractions. Test authors work with pandas DataFrames while the framework handles serialization, gRPC requests, and result parsing.
Test Execution
Validates model compatibility through a file-based testing endpoint. The service reads model and feature files, performs inference, and writes scores to output files for validation. This workflow confirms that trained models can be loaded, served, and queried correctly before production deployment.
Dynamic Model Loading
Auxia’s dynamic model‐loading system allows customer requests to specify models by name and digest, then transparently fetches, validates, and serves those models without inference server restarts.
Model Distribution
Models are published as OCI images in Google Cloud Artifact Registry. Each image contains a TensorFlow SavedModel at /data/tensorflow_serving_model/model and a metadata.json file describing input/output contracts. This enables ML Engineers and Data Scientists to push new versions frequently with floating labels (latest, canary) for rapid production deployment.
Runtime Architecture
Incoming gRPC Predict requests route through a ModelRegistry that dispatches to appropriate ModelLoaders based on model name prefixes. For container-based TensorFlow models:
DockerModelLoader resolves fully qualified image names, handles live and canary tags, fetches image manifests, and produces lightweight specs pointing to chosen digests
TensorflowModelLoader stages models on disk and orchestrates two coordinated state machines maintaining synchronization between our internal view and TensorFlow Serving's configuration
State Machine Management
ModelStateMachine manages individual model lifecycles:
NEW → DOWNLOADED (files staged locally)
DOWNLOADED → LOADED (reload-config sent to TensorFlow Serving)
LOADED → AVAILABLE (GetModelStatus confirms serving readiness)
Idle models automatically unloaded and deleted after configurable duration
Read/write mutex guards with backoff timers for transient failure handling
TFServingStateMachine aggregates all loaded models into a single ModelServerConfig, pushing updates via ReloadConfigRequest API. This prevents race conditions between concurrent operations and handles known TensorFlow Serving bugs where unknown-status errors indicate successful reloads.
Both state machines run in Kotlin coroutines on dedicated dispatchers, ensuring asynchronous operation without blocking server I/O threads.
Canary deployments are first‐class features of our architecture. Models tagged with _canary trigger the Docker loader to read ModelCanaryConfig protobuf from image labels, specifying traffic fraction and monitoring parameters.
The system probabilistically routes specified percentages of requests to new versions while maintaining traffic to live versions. Canary models are pre-warmed to minimize latency spikes, and automated monitoring of latency, error rates, and output distributions drives promotion or rollback decisions.
This dynamic loading system provides robust, zero-downtime model lifecycle management enabling rapid experimentation and safe production rollouts.
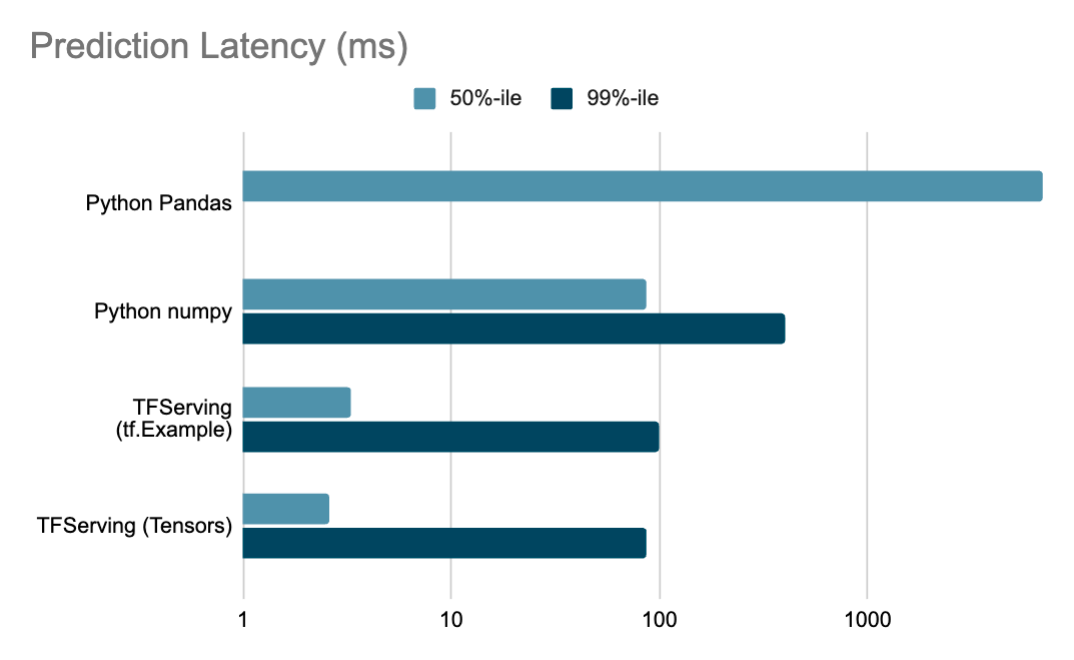
Latency and Performance Improvement
Our optimizations delivered significant latency improvements across the inference pipeline:
Note: Latency scale is logarithmic. Figures based on load-tested results under heavy serving pod load. Production figures can be 10x better at 99th percentile. No 99% latency data available for Python Pandas baseline.
The combination of optimized input contracts, efficient batching, and dynamic model management allows us to meet our ambitious performance targets while maintaining the flexibility needed for rapid ML experimentation and deployment.