グロースレコメンデーションのためのスケーラブルな推論基盤
![]() Auxiaチーム7月 31, 202515 分
Auxiaチーム7月 31, 202515 分
Auxiaは、エージェント ベースのカスタマー ジャーニー オーケストレーション・プラットフォームであり、エンタープライズ顧客に対してパーソナライズされたマーケティング施策を提供します。顧客企業は、アプリ内、メール、その他のデジタル体験において、APIを通じて「Decision(施策)」と呼ばれるレコメンデーションを取得することで、Auxiaと統合します。
エンタープライズ向けにサービスを提供する場合、インフラは必然的に大規模なスケーリングの課題に直面します。現在Auxiaでは、秒間6,000件を超えるリクエストを処理しており、予測レイテンシの99パーセンタイルを100ms以下に抑えることを目指しています。各リクエストでは、およそ1,000通りのユーザー向け施策から最適なものを選定する必要があります。
本記事では、こうした要件を満たすために構築した高性能な推論基盤について詳しくご紹介します。
リアルタイムパーソナライゼーションをスケーリングする
私たちAuxiaでの、アーキテクチャの意思決定では、3つの重要要件があります:
高スループット、低レイテンシ処理:数千の同時リクエストに対して100ms未満で応答
リアルタイムの文脈データ統合:新鮮なユーザー文脈や行動データを推論に取り込む
マルチテナントモデル対応:顧客と目標の組み合わせごとに異なるモデルでの同時推論を実現
これらの要件の組み合わせにより、ロードバランスされたサービスインスタンス間で動的にモデルを読み込める、高性能なリアルタイム推論システムが求められました。
アーキテクチャ:Kotlin + TensorFlow Serving Sidecar
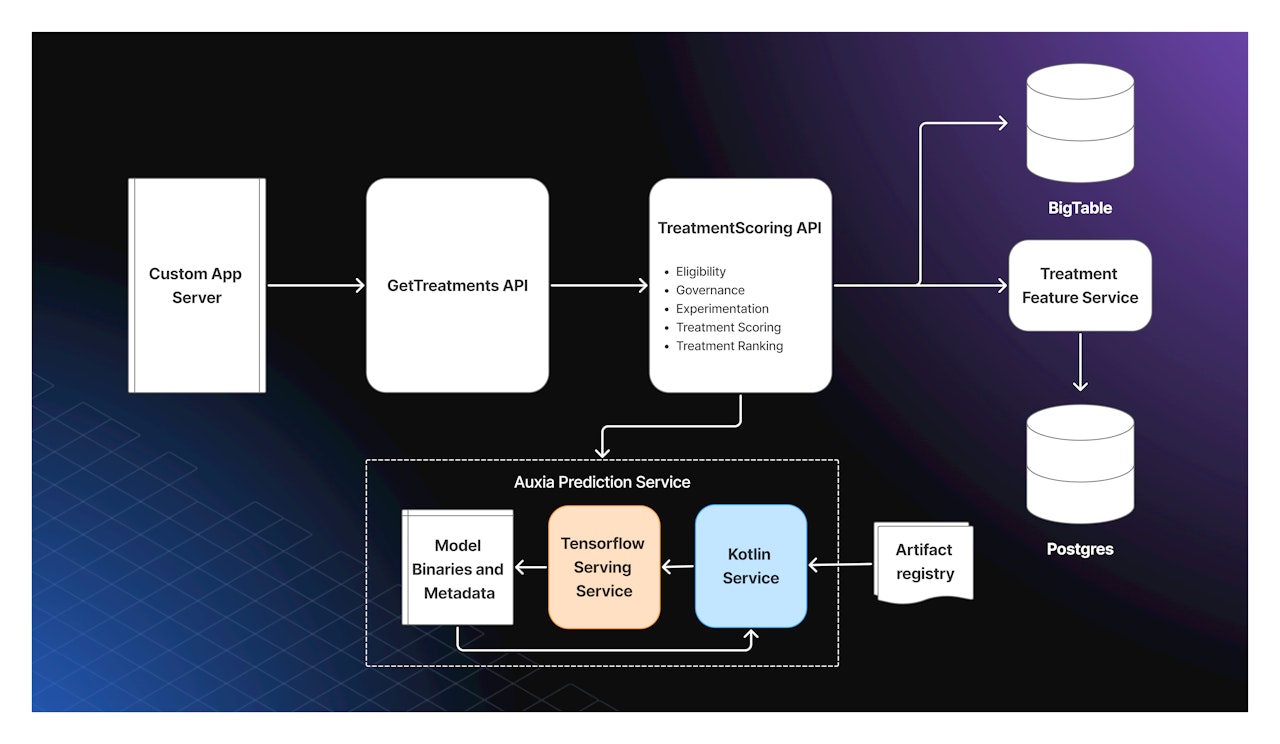
私たちは、Kubernetesポッド内にKotlinサーバ(制御プレーン)とTensorFlow Servingバイナリ(推論エンジン)を同居させる構成を採用しました。この設計により、懸念事項の明確な分離を保ちつつ、高性能と柔軟性の両立を実現しています:
Kotlinサーバー:動的なモデル読み込み、モデルメタデータの管理、入出力テンソル変換、ライフサイクル・オーケストレーション
TensorFlow Serving:gRPCベースのAPIにより、学習済み TensorFlow モデルに対する高速な推論処理を提供
モデルロジックはTensorFlow側に隔離され、オーケストレーションやビジネスロジックはKotlinサーバーに集中する設計となっています。
Kotlin + gRPCの技術基盤を持つ私たちにとって、この設計はKotlinの強み(特に非同期プログラミングにおけるコルーチン)を活かしつつ、機械学習インフラの複雑さを抽象化します。Kotlin層では以下を担当しています:
インフラ抽象化:さまざまなモデル形式(ONNX、TorchServe、ホステッドサービス)にも対応できる構造
動的モデル管理:Artifact Registryからモデルを読み込み、TensorFlow ServingのModelServiceを管理
形式変換:ユーザーや施策の特徴をモデル入力用のテンソルへ変換し、出力されたテンソルを施策スコアへ戻す
TensorFlow Servingを選んだ理由
TorchServeのような代替案ではなく、TensorFlow Servingを選定した理由は以下のとおりです:
gRPC APIの利点:強い型付けとプログラマティックに定義されたインターフェースで、バイナリ シリアライズにより通信サイズと CPU負荷を削減。大量の特徴量を扱うAuxiaにおいて特に重要
高パフォーマンス:即時的な意思決定モデルを可能にする、ネィティブでマルチスレッド処理に最適化された C++ 実装
本番環境向けの機能:動的モデル読み込みの対応や自動バッチ推論への組み込み対応
一方で、以下のような課題もあり、Kotlin 側で補完しています:
動的読み込みの制約:技術的には動的読み込みには対応しているが、当初のバイナリは静的なモデルに最適化されている
実運用での検証不足:コンテナ内でのCPU誤認識など現場ならではの問題が発生
最適化要件:すべてのTensorFlow演算が高速とは限らないため、モデル形式の設計が重要
推論抽象化レイヤー
AuxiaのPrediction (推論) Service は、推論の複雑さを抽象化し、施策を軸に開発されたシンプルなAPIを提供しています。この抽象化により、様々なモデルアーキテクチャーをサポートできています。例えば、バンディット (Bandit) アルゴリズムやツリーベース のアップリフトモデル、そして深層学習を使った推薦モデルなどをサポートしています。
主な特徴:
統一API:一貫性のある一つのインターフェースを提供し、基盤となるモデル実装に依存しない。ユーザー特徴量はkey-value形式または構造化オブジェクトで、施策特徴量はkey-valueで受け取り、出力形式も明確に定義(単一スコアまたは施策ごとのスコアリスト)
動的モデル管理:サーバー再起動不要でモデルの入れ替えが可能、継続的な実験や改善を促進
システムに組み込まれたモニタリング:すべてのモデルから排出される予測におけるレイテンシやエラー率を自動収集し、システムの信頼性を担保
開発者向けツール:モデルを検証する機能や検証用の環境でも安全にテストできる APIを用意
推論最適化のための入力形式設計
TensorFlow Servingは、フラットな名前空間のテンソルを入力として要求します(テンソル名とデータをマッピングした辞書)。Python版TensorFlowが対応するような入れ子構造(辞書、RaggedTensorsなど)とは異なり、より厳密な制約があります。これにより、スケール時における構造化特徴量の表現が課題となります。
最適化までの試行錯誤:
初期方式:特徴ごとに個別テンソルを作成し、特徴名を鍵にする。これは実装は簡単ですが、膨大なテンソル数のシリアライズ・名前解決のコストにより効率が悪い
tf.Example形式:TensorFlow標準のシリアル形式にエンコード する。こちらはProtoパースが重く、遅延が改善されなかった
最終方式(最適化済):同じ特徴を1つの均一型のテンソルにまとめ、インデックスで識別 をする。この手法ではテンソル数を最小化しながらも、TensorFlowの内部にある特徴レゾリューションと同調
実装詳細
ユーザー特徴量:例えば [None, 4] 型の数値テンソルで表現、インデックスは特定の特徴に準ずる(signup age、LTVなど)
施策特徴量: [None, None, N] 形式のテンソルでユーザーあたり複数の施策に対応し、treatment_countsテンソルでユーザーごとの区切りを示す
GPU最適化:TensorFlow Servingの自動バッチ機能を活用。treatment_countsテンソルでパディング除去や区切り再構築を処理
メタデータ管理:トレーニングと推論時の整合性を保つため、テンソルindexと特徴名の対応をメタデータファイルで管理
この最適化された設計により、p99レイテンシを100ms未満に抑えながらリクエストごとに最大1,000施策をスコアリングを、6,000QPS で提供することができました。
サービングモデル検証フレームワーク
すべての学習済みモデルは、Prediction Service APIと互換性を持つ必要があります。そのため、次の3段階からなる包括的なローカルテストフレームワークを構築しました:
環境構築
Kotlin Prediction ServiceとTensorFlow Servingを含む完全な本番相当スタックをローカルに起動
モックではなく実際のバイナリで検証可能
テストオーケストレーション
pytestと補助クラスで管理
モデル配置や高レベルのクライアント操作を抽象化
テスト記述者はpandas DataFrameで操作し、裏側でテンソル変換、gRPCリクエスト、レスポンス解析が行われる
テスト実行
ファイルベースの検証エンドポイントでモデルと特徴ファイルを読み込み、スコアを出力ファイルに保存して整合性を検証
運用環境配備前に、モデルが正常に読み込まれ推論可能かを確認
動的モデル読み込み
Auxiaの動的モデル読み込みシステムでは、クライアントからのリクエストごとにモデル名とダイジェスト(内容のハッシュ)を指定できます。それに応じて、対応するモデルを透過的に取得・検証・サービングするため、推論サーバの再起動は不要です。
モデル配布
モデルは、Google Cloud Artifact Registry に OCI イメージとして公開されます。各イメージには、以下のような内容が含まれます:
TensorFlow SavedModel(/data/tensorflow_serving_model/model)
入出力形式を記述した metadata.json ファイル
これにより、機械学習エンジニアやデータサイエンティストが頻繁にモデルを更新し、latest や canary などのフローティングタグで本番環境に素早く反映できるようになります。
実行時アーキテクチャ
受信した gRPC Predict リクエストは、ModelRegistry を経由して適切な ModelLoader にルーティングされます。TensorFlowモデル用のコンテナに関しては、次のようなフローです:
DockerModelLoader:完全修飾画像名を解決し、live や canary タグを処理、イメージマニフェストを取得し、対象の Digest に基づいた軽量な spec を生成
TensorflowModelLoader:モデルをローカルに配置し、2つの状態マシンを協調して管理。Auxia側の内部状態とTensorFlow Serving側の構成が常に同期するよう調整
ステートマシン管理
ModelStateMachine 各モデルのライフサイクルを管理:
NEW → DOWNLOADED:ローカルにファイルをステージング
DOWNLOADED → LOADED:TensorFlow Servingに構成リロードを送信
LOADED → AVAILABLE:GetModelStatus APIでServingの準備完了を確認
一定時間に使用されなかったモデルは自動的にアンロード&削除。時間は調整が可能
一時的な障害処理のためのバックオフタイマー付き読み書きミューテックスガード
TFServingStateMachine 全モデルの統合状態を管理:
すべてのロード済みモデルを1つの ModelServerConfig に集約
ReloadConfigRequest API を通じて一括更新を行うことで、操作競合や TensorFlow Serving の既知バグ(unknown-status エラーなど)にも対応
両ステートマシンは、Kotlin のコルーチン上で専用ディスパッチャーを使って非同期に動作するため、サーバーの I/O スレッドをブロックすることはありません。
Auxiaでは、Canary デプロイを正式にサポートしています。機能はアーキテクチャに組み込んであり、_canary タグ付きモデルを検出すると、Docker loader が ModelCanaryConfig protobuf をイメージ ラベルから読み取り、トラフィックの振り分け比率やモニタリングパラメータを設定しています。
本システムは、リクエストの一部を新バージョンに確率的にルーティングしながら、ライブバージョンへのトラフィックを維持しています。カナリアモデルは事前にウォームアップされるため、レイテンシのスパイクの発生を最小化しています。レイテンシ、エラー率、出力分布のモニタリングにより、プロモーションまたはロールバックが自動的に判断されます。
この仕組みにより、ゼロダウンタイムでのモデルライフサイクル管理が可能になり、安全かつ迅速な実験と本番展開が実現します。
レイテンシとパフォーマンスの改善
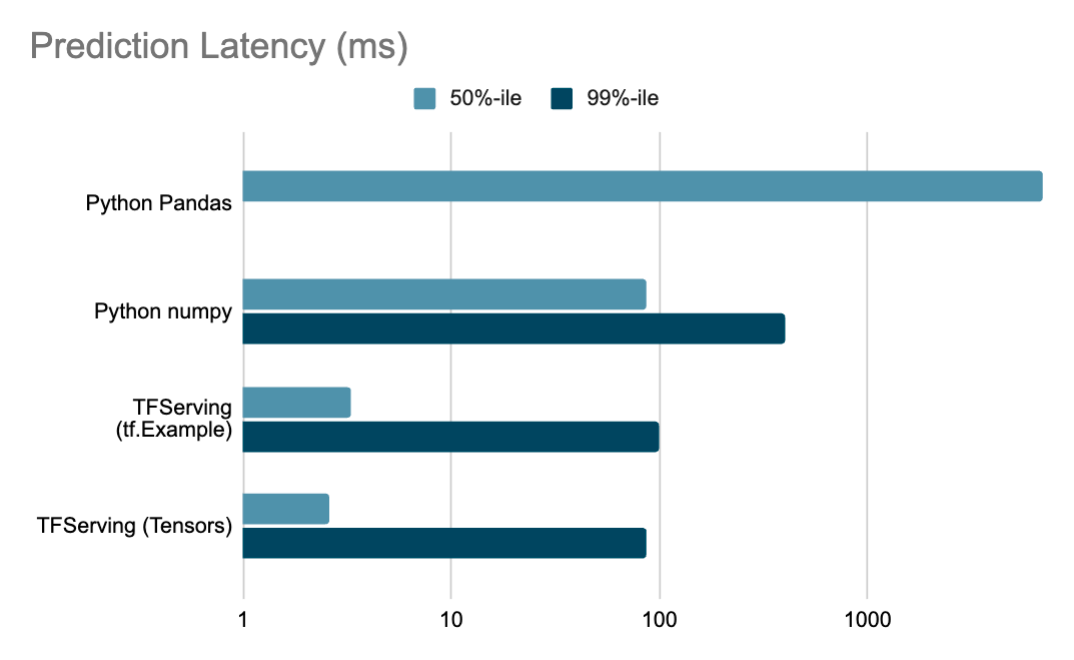
Auxia の最適化により、推論パイプライン全体で大幅なレイテンシ改善を達成しました
注:レイテンシのグラフは対数スケールで示されています。数値は高負荷状態下での負荷テスト結果に基づいており、本番環境ではさらに10倍速いこともあります。Python Pandas をベースとした旧システムでは 99 パーセンタイルのデータは存在しません。
入力形式の最適化、効率的なバッチ処理、動的モデル管理の組み合わせにより、Auxiaは高い性能目標を満たしながらも、機械学習の迅速な実験と展開に必要な柔軟性を維持しています。
詳しくは、ぜひ Auxiaの公式サイトよりお問い合わせください。